Welcome to Sparkhit
Sparkhit is an open source distributed computational platform for analyzing large-scale genomic datasets. It is built on top of the Apache Spark and Hadoop framework, integrates a series of bioinformatics tools and methods. Here you can parallelize different analytical modules, such as sequence mapping, genotyping, gene expression quantification and taxonomy profiling. You can also use your own tools without changing the source code. For distributed parallel De novo genome assembly, please visit Reflexiv.
How it works
Sparkhit uses Spark RDD (resilient distributed dataset) to distribute genomic datasets: sequencing data, mapping results, genotypes or expression profiles of genes or microbes. A Spark extended MapReduce paradigm is used to analyse these datasets in parallel.
Read more: Analyzing large scale genomic data on the cloud with Sparkhit. Bioinformatics. 2017.
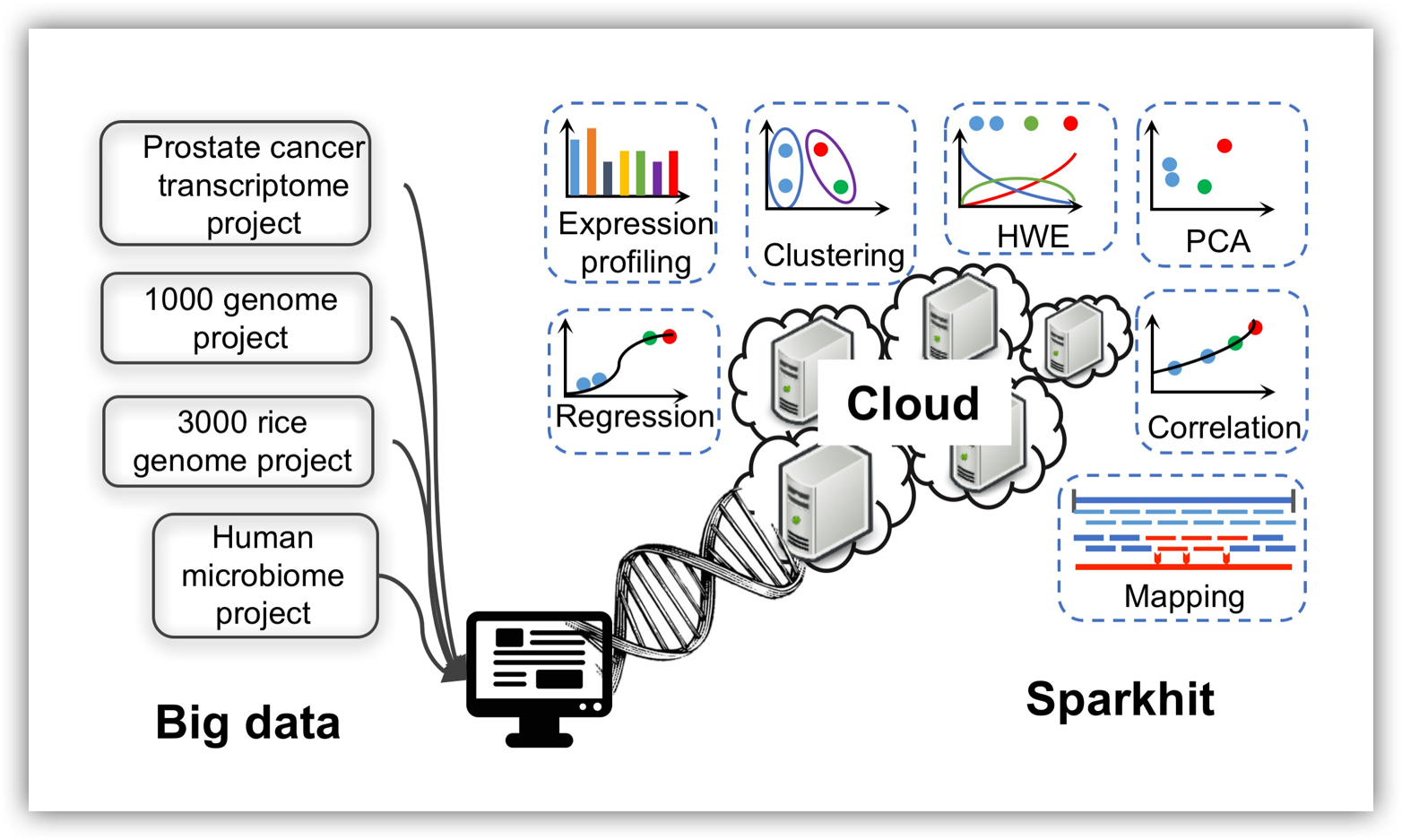
Getting started
Follow the tutorial to run a simple Sparkhit application on your laptop.
Use your own tool
Sparkhit facilitates users to use their own tools without changing the source code.
Command:
/usr/bin/sparkhit piper \ --driver-memory 4G \ ## Spark parameter --executor-memory 8G \ ## Spark parameter -input '/vol/human-microbiome-project/SRS*.tar.bz2' \ # Sparkhit parameter -tool /vol/sparkhit-home/package/mycode/myMappingScript.sh \ # Sparkhit parameter -toolparam "-reference /vol/singlecell/genome.fa" \ # Sparkhit parameter -output /vol/mybucket/sparkhit/result # Sparkhit parameterRead more.
Parallelize Docker containers
Sparkhit enables users to parallelize public biocontainers, e.g. Docker.
Command:
/usr/bin/sparkhit piper \ --driver-memory 4G \ ## Spark parameter --executor-memory 8G \ ## Spark parameter -input '/vol/human-microbiome-project/SRS*.tar.bz2' \ # Sparkhit parameter -tooldepand docker \ # Sparkhit parameter: use docker -tool run \ # Sparkhit parameter: use docker run -toolparam "-iv /sparkhitData/dataset:/tmp -w /tmp --rm \ # Sparkhit parameter: docker options lh3lh3/bwa mem reference.fa /dev/stdin" \ # Sparkhit parameter: docker image "bwa" -output /vol/mybucket/sparkhit/result # Sparkhit parameterRead more.
Setup cluster
A Spark cluster is essential to scale-out (distribute to multiple compute nodes)
Support or Contact
Having troubles using
Acknowledgement
We acknowledge all developers whose tools are used by Sparkhit.